

Getting Started
Step-by-step guide to building a RAG application with Index, including index setup, configuration, and integration with your application.
Overview
Section titled “Overview”Index is part of the LlamaCloud platform (which includes LlamaParse, LlamaExtract, LlamaAgents, and other products). It makes it easy to set up a highly scalable & customizable data ingestion pipeline for your RAG use case. No need to worry about scaling challenges, document management, or complex file parsing.
Index offers all of this through a no-code UI, REST API / clients, and seamless integration with our popular python & typescript framework.
Connect your index to your data sources, set your parse parameters & embedding model, and the index automatically handles syncing your data into your vector databases. From there, we offer an easy-to-use interface to query your indexes and retrieve relevant ground truth information from your input documents.
Prerequisites
Section titled “Prerequisites”- Sign up for an account
- Prepare an API key for your preferred embedding model service (e.g. OpenAI).
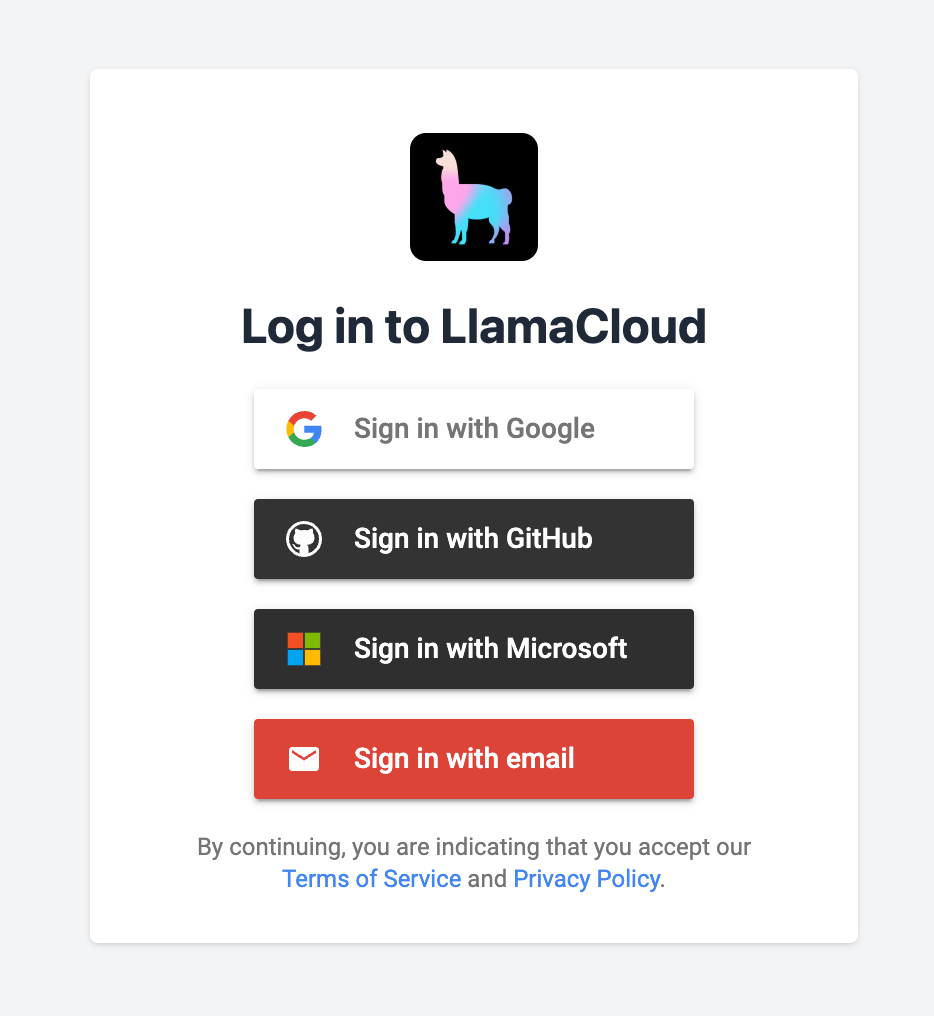
Sign in
Section titled “Sign in”Sign in via https://cloud.llamaindex.ai/
You should see options to sign in via Google, Github, Microsoft, or email.
Set up an index via UI
Section titled “Set up an index via UI”Navigate to Index feature via the left navbar.
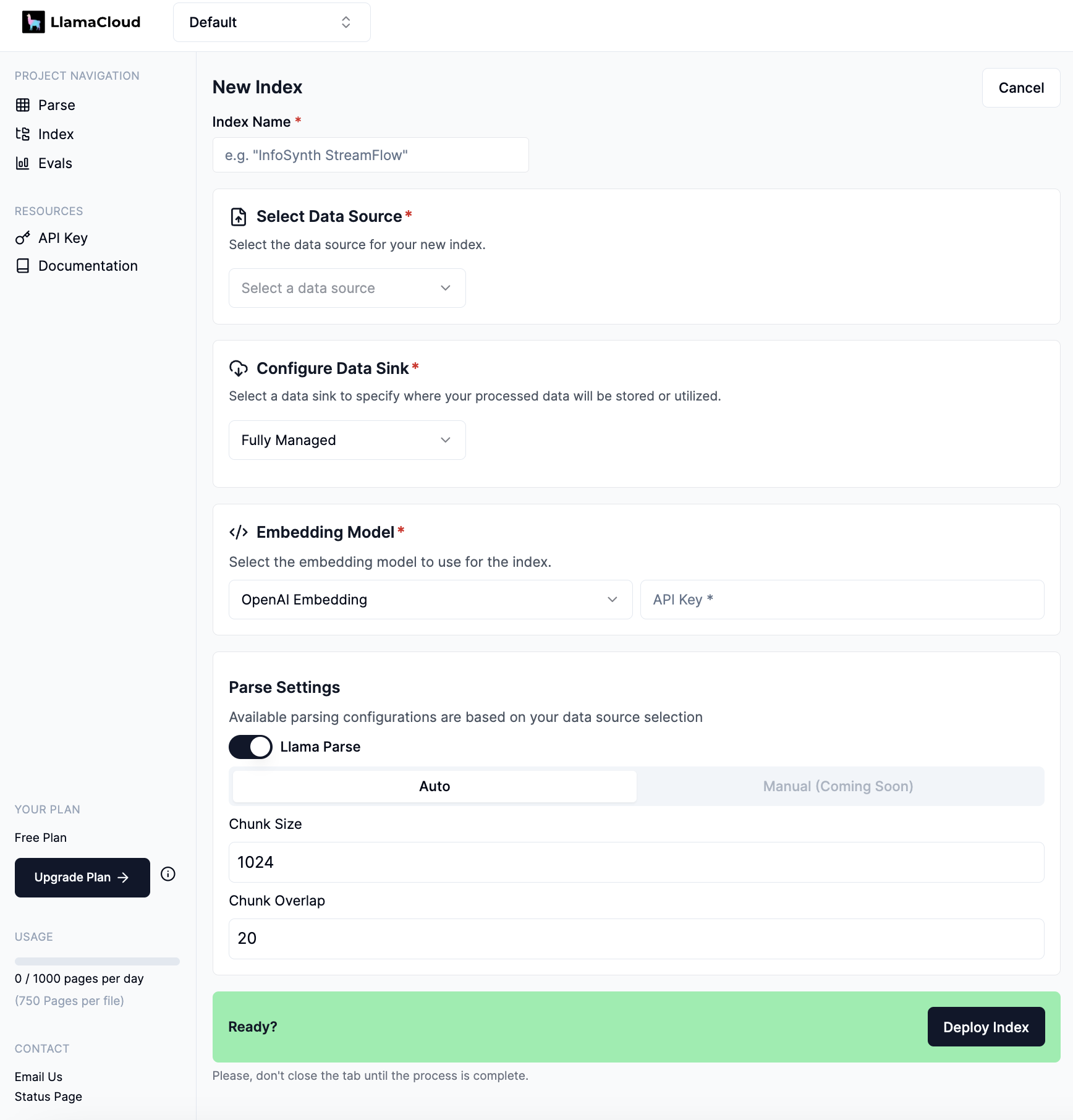
Click the Create Index button. You should see a index configuration form.
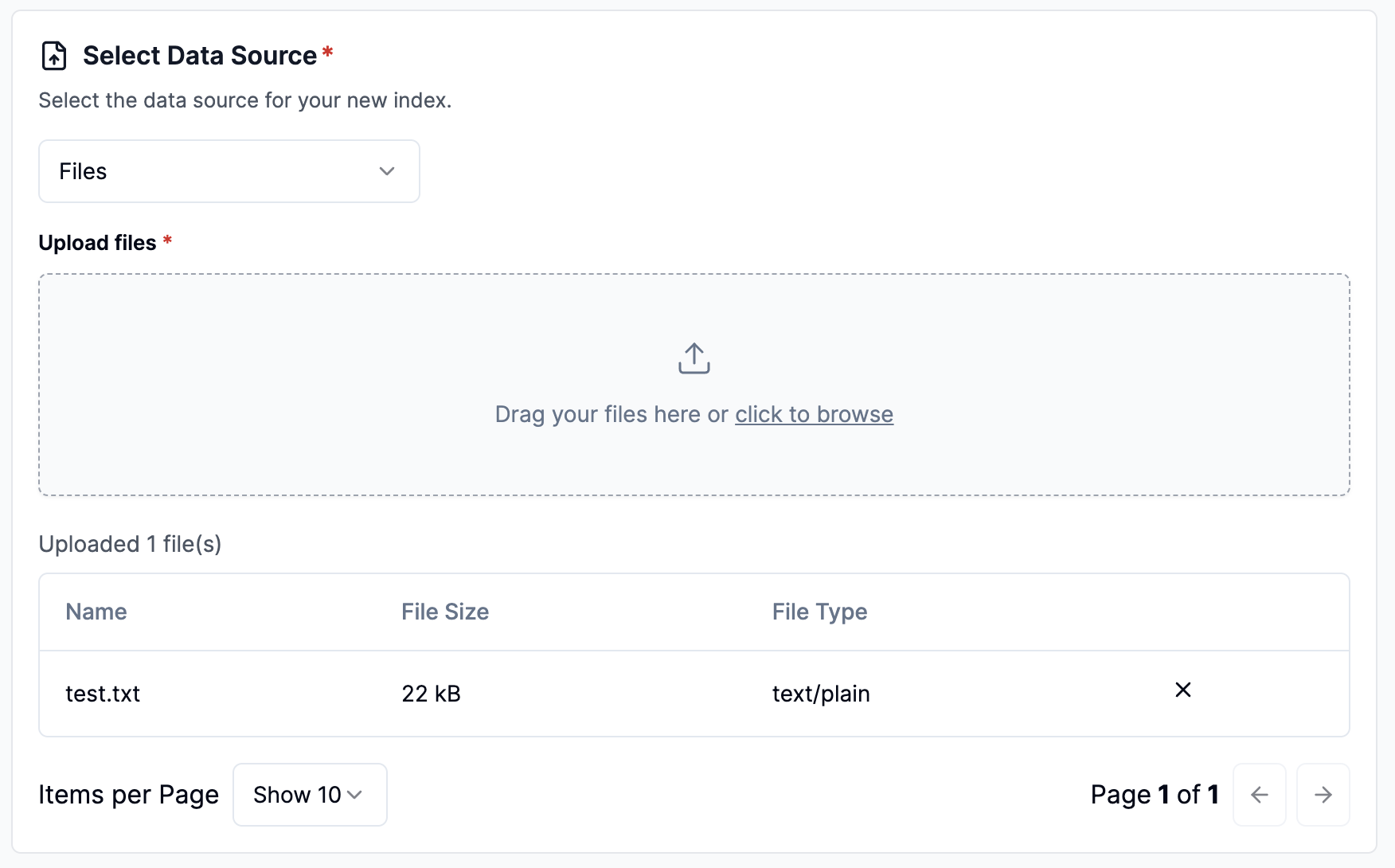
Configure data source - file upload
Click Select a data source dropdown and select Files
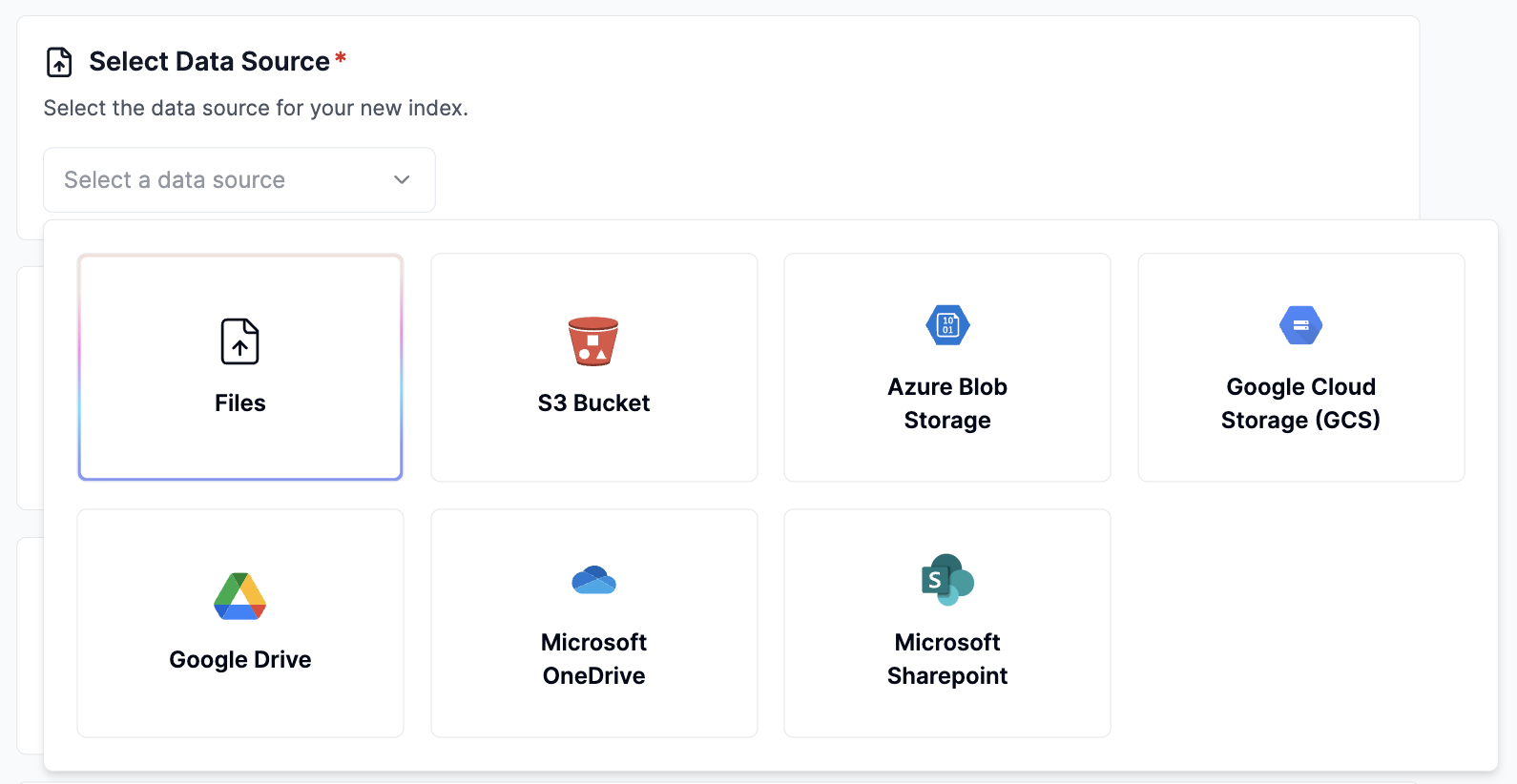
Drag files into file pond or click to browse.
Configure data sink - managed
Select Fully Managed data sink.

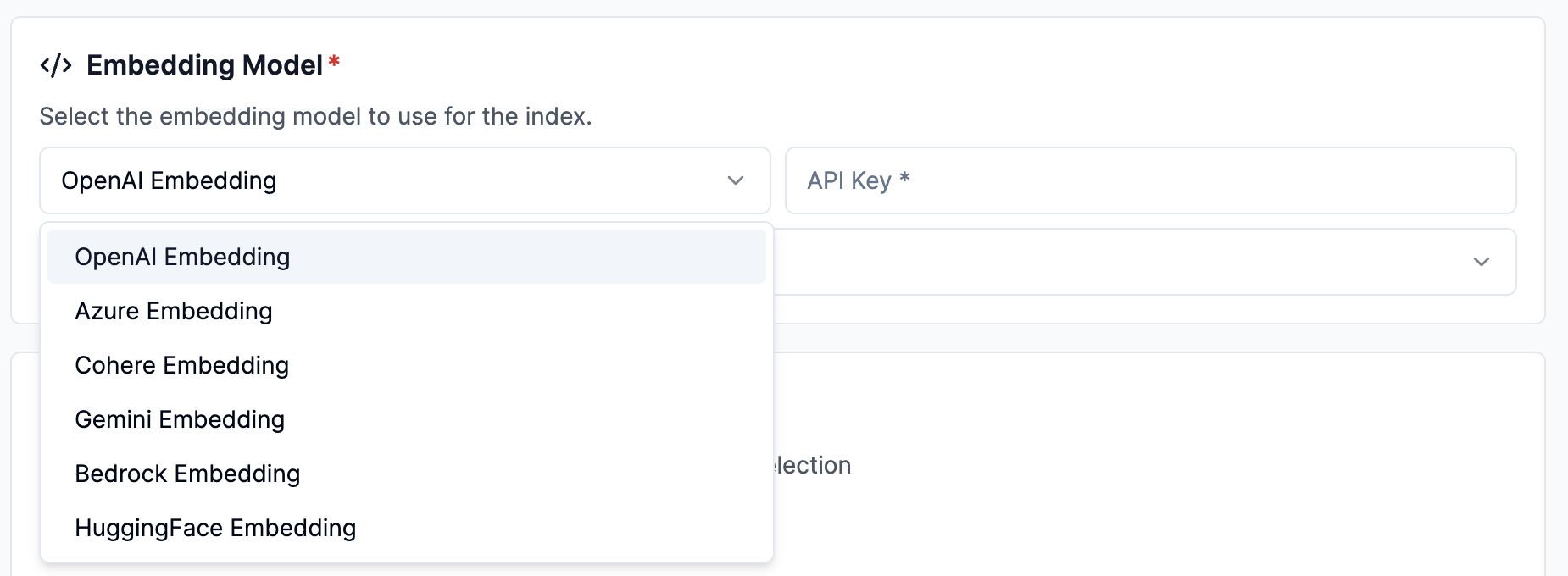
Configure embedding model - OpenAI
Select OpenAI Embedding and put in your API key.
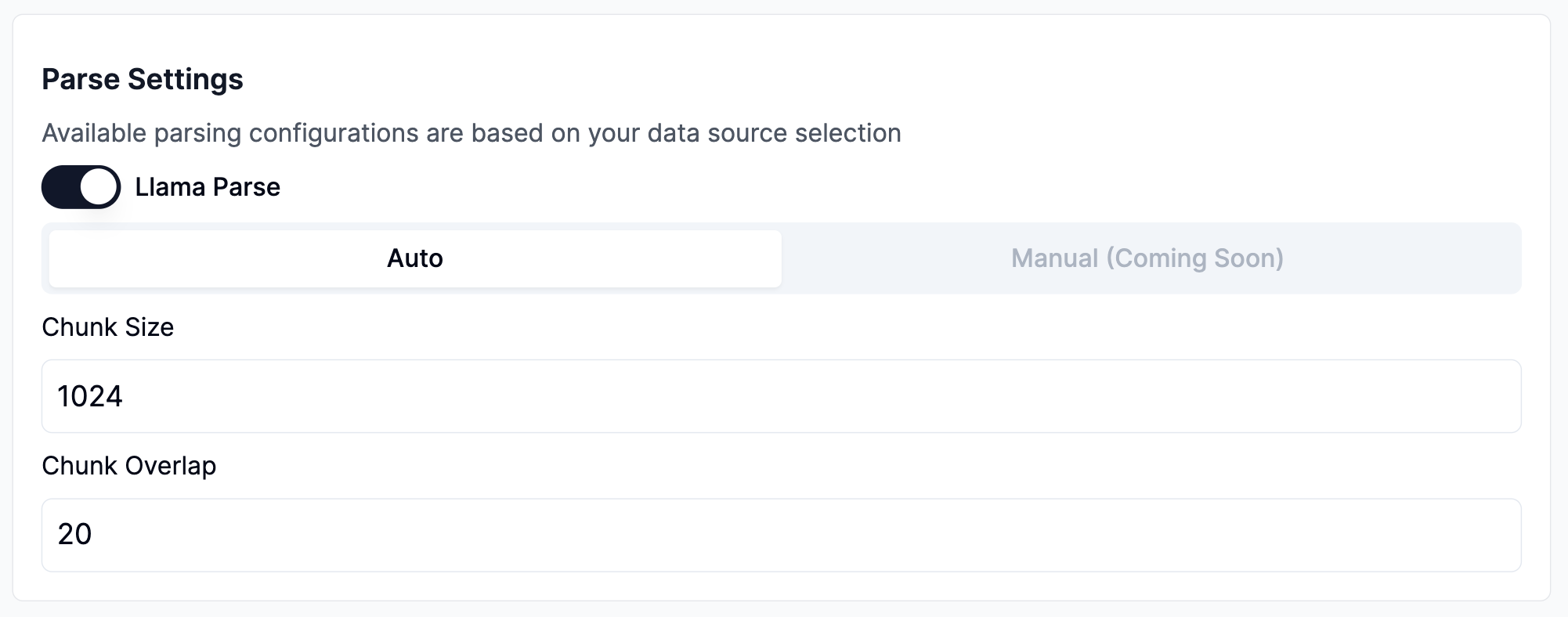
Configure parsing & transformation settings
Toggle to enable or disable Llama Parse.
Select Auto mode for best default transformation setting (specify desired chunks size & chunk overlap as necessary.)
Manual mode is coming soon, with additional customizability.
After configuring the ingestion pipeline, click Deploy Index to kick off ingestion.

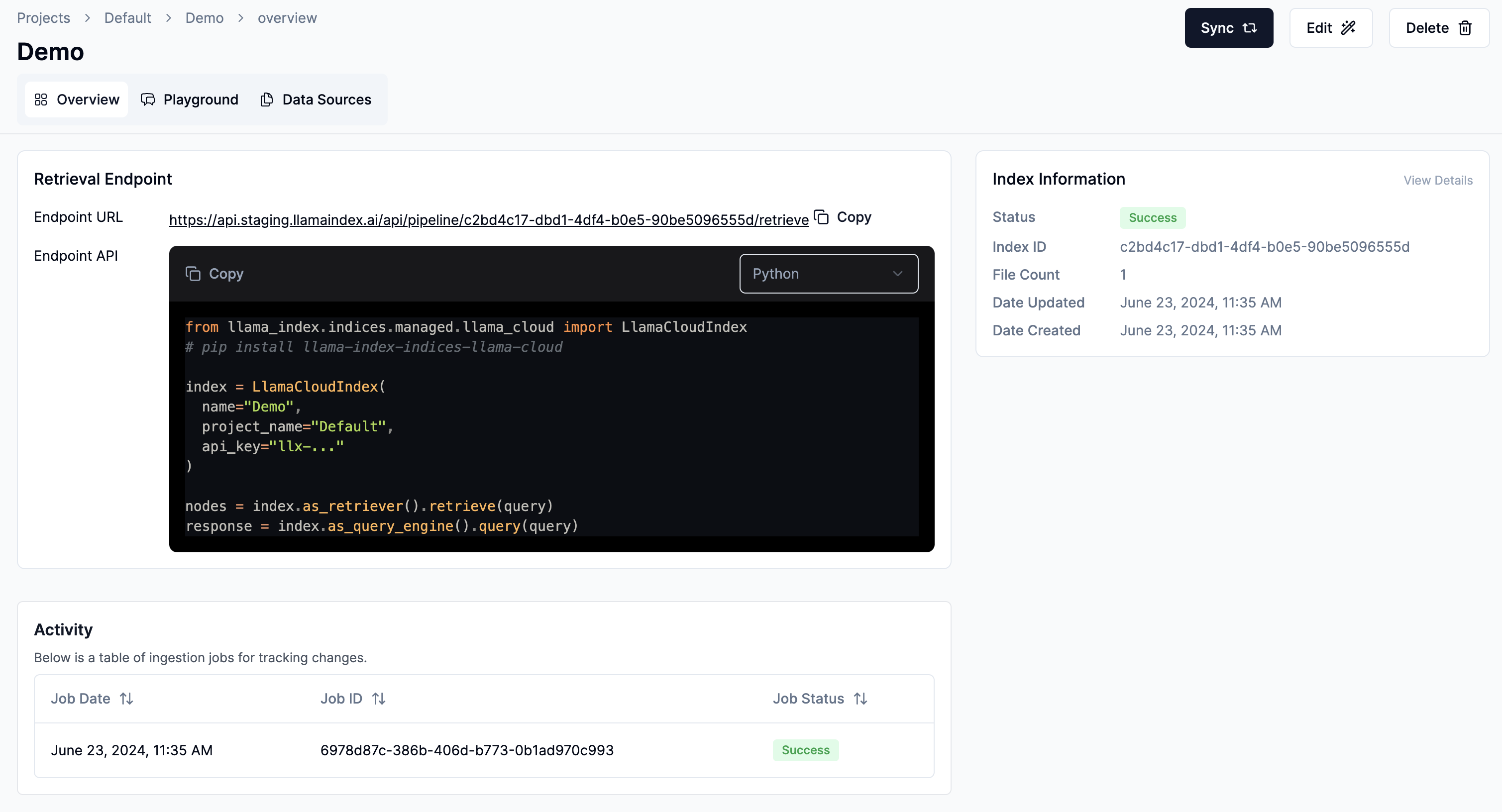
(Optional) Observe and manage your index via UI
Section titled “(Optional) Observe and manage your index via UI”You should see an index overview with the latest ingestion status.
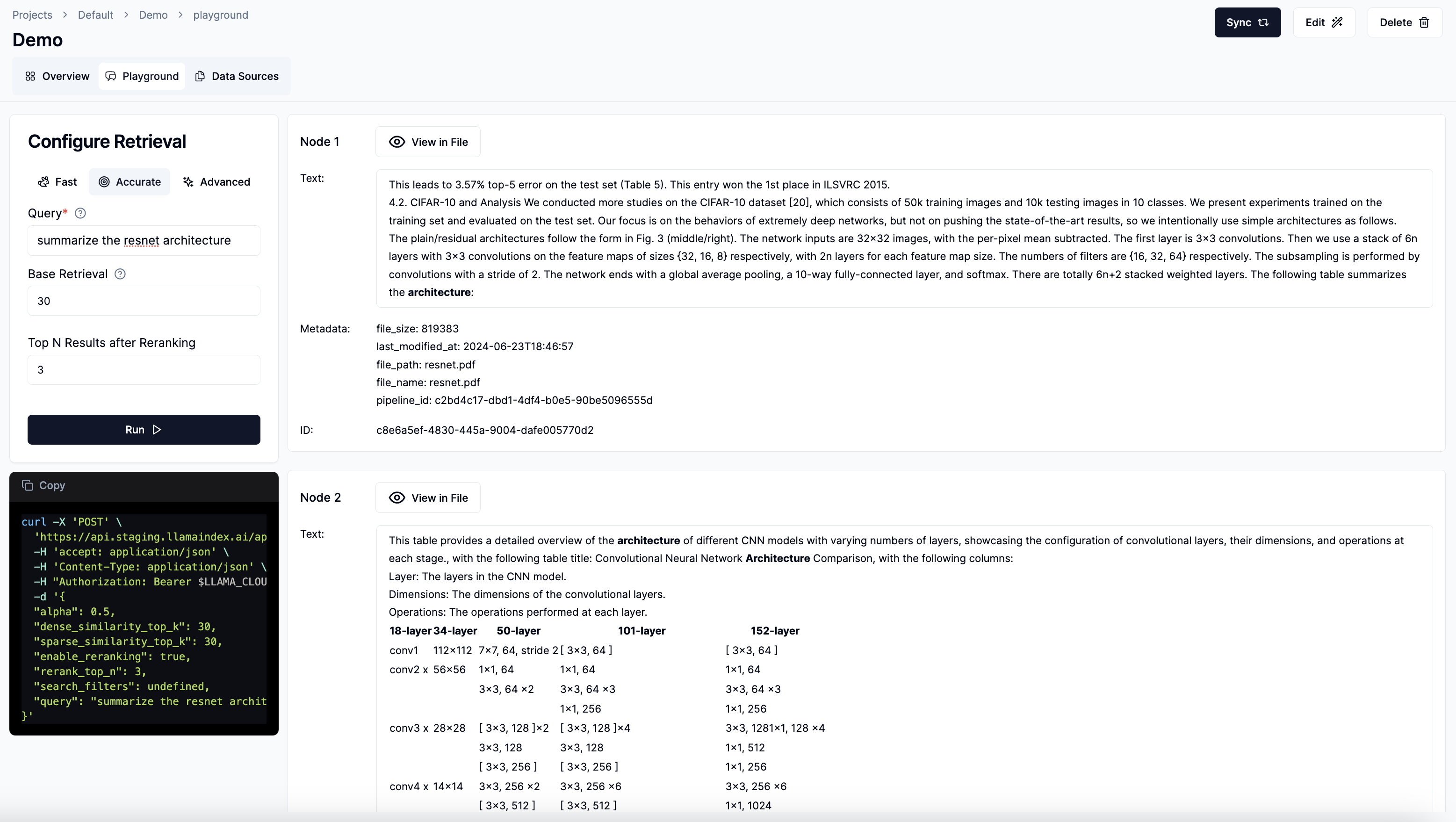
(optional) Test retrieval via playground
Navigate to Playground tab to test your retrieval endpoint.
Select between Fast, Accurate, and Advanced retrieval modes.
Input test query and specify retrieval configurations (e.g. base retrieval and top n after re-ranking).
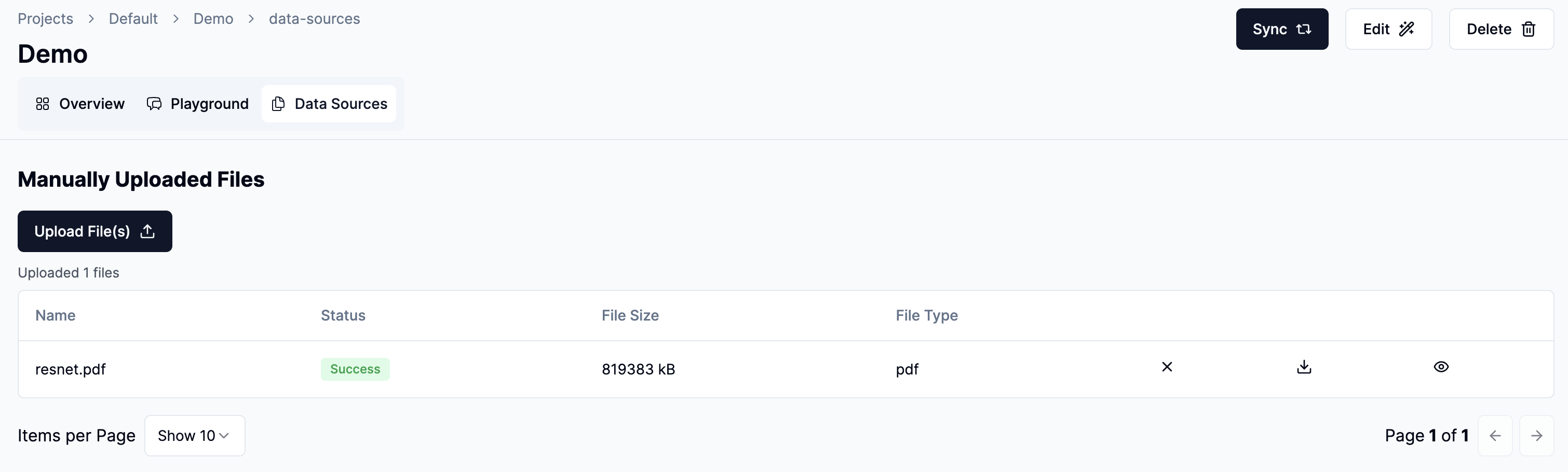
(optional) Manage connected data sources (or uploaded files)
Navigate to Data Sources tab to manage your connected data sources.
You can upsert, delete, download, and preview uploaded files.
Integrate your retrieval endpoint into RAG/agent application
Section titled “Integrate your retrieval endpoint into RAG/agent application”After setting up the index, we can now integrate the retrieval endpoint into our RAG/agent application. Here, we will use a colab notebook as example.
Obtain LlamaCloud API key
Navigate to API Key page from left sidebar. Click Generate New Key button.
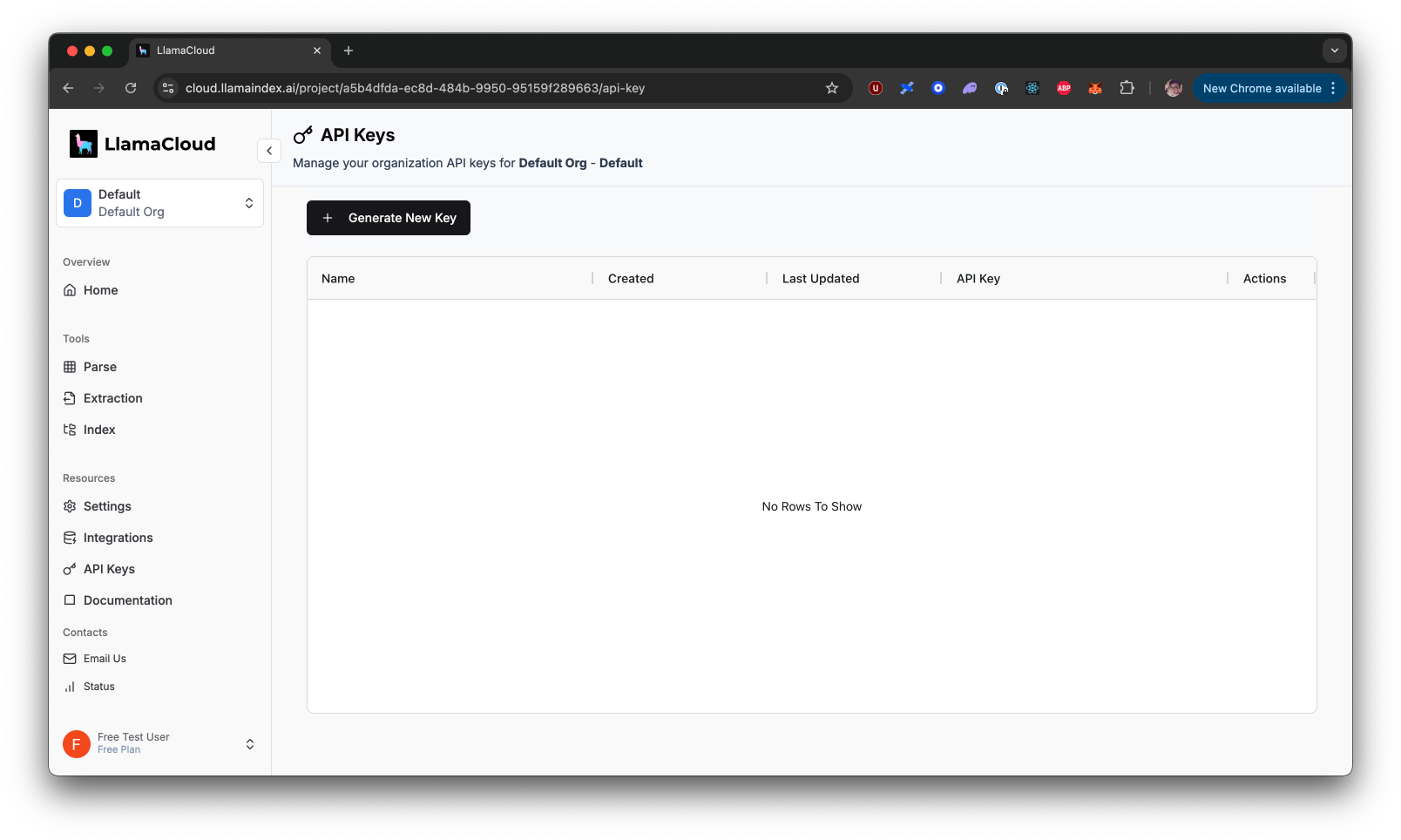
Copy the API key to safe location. You will not be able to retrieve this again. More detailed walkthrough.
Setup your RAG/agent application - python notebook
Install latest python framework:
pip install llama-indexNavigate to Overview tab. Click Copy button under Retrieval Endpoint card
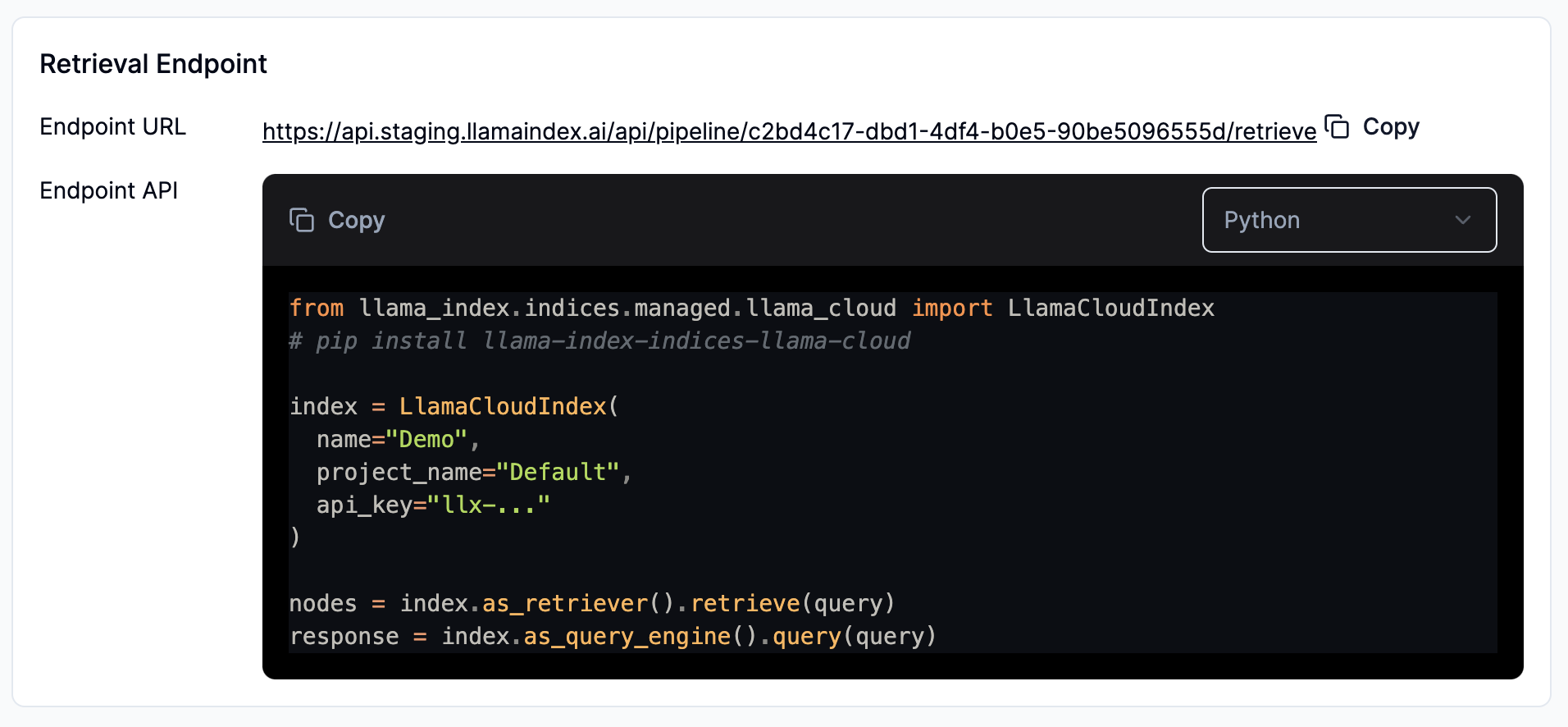
Now you have a minimal RAG application ready to use!
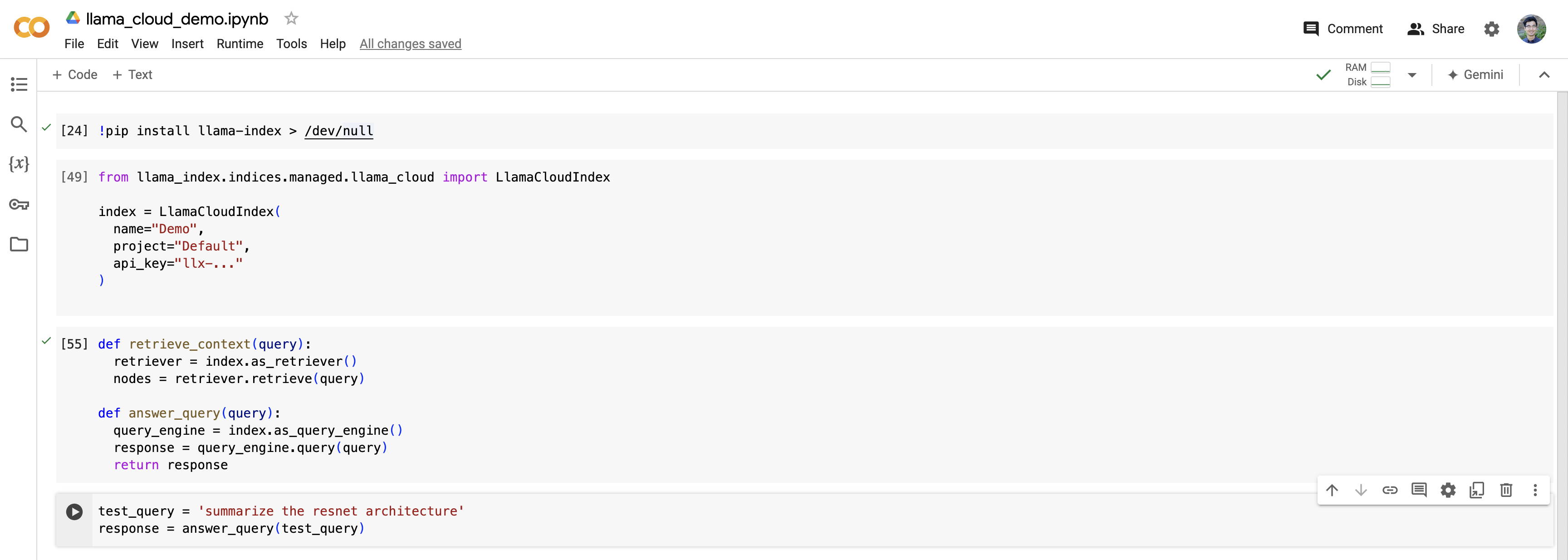
You can find demo colab notebook here.